제미나이도 MBTI에 대한 범용적인 질문은 충분히 대답을 잘 해준다.
하지만, 내가 만들고자 하는 서비스에서는 T 또는 F의 특징을 바탕으로 의도를 파악하고 상대방의 입장으로 번역하고 통역하는 기능이 필요하다.
처음에는 제미나이에게 바로 'F의 말을 T의 언어로 번역해줘'라고 요청하면 될 줄 알았지만 정확한 의도를 표현하지 못하고 있었다.
그래서 MBTI 관련 자료를 외부 데이터로 넣어서 RAG를 통해 더 정확한 답변을 얻을 수 있도록 해보려고 한다.
RAG란?
먼저 RAG에 대해 알아보자.
- 검색 증강 생성(Retrieval-Augmented Generation)이라는 뜻으로, 기존의 LLM 모델에 외부 데이터를 추가해 더 정확한 답변을 생성하는 기술이다.
등장하게 된 배경
- 기존의 LLM 모델은 학습한 내용을 기반으로 동작하기 때문에 최신 정보를 반영하지 못하거나, 그럴듯한 답이지만 사실이 아닌 내용을 만들어서 답변하는 환각(할루시네이션)문제가 존재했다.
- 범용적인 질문에 대한 답변은 잘 하지만, 특정 분야의 깊은 질문에 대한 답변은 어려웠다.
- 파인튜닝을 통해 LLM을 특정 분야에 적합하게 만드는 방법도 있지만, 파인튜닝을 진행하는 것은 많은 비용과 시간이 소요되며 어려운 작업이다.
따라서 LLM은 그대로 둔 채 검색을 통한 외부 데이터와 LLM을 연결하여 더 정확하고 신뢰할 수 있는 답변을 생성하는 방법이 등장하게 되었다.
RAG를 활용하면, 기존의 제미나이나 GPT에 MBTI F/T에 대한 정보를 추가해 여기에 특화된 답변을 받도록 조정할 수 있게 되는 것이다.
RAG는 프롬프트 엔지니어링, 벡터화, 벡터 데이터베이스 등 여러가지 기술이 모여서 만들어진 집합체이다.
RAG를 개발하기 전에 먼저 필요한 기초 개념들을 하나씩 정리해보자.
1. 프롬프트 엔지니어링
2. 벡터화 & 임베딩
3. 벡터 데이터베이스
1. 프롬프트 엔지니어링
프롬프트 엔지니어링은 AI가 어떻게 행동하고 어떤 정체성을 가지고 작업을 수행하며 답변을 생성할지 정의하는 지침이다. 간단한 질문은 프롬프트만 잘 작성해도 원하는 형태의 답변을 얻을 수 있다
왜 중요할까?
- 특히 시스템 프롬프트는 LLM의 초기 설정값을 지정해주는 프롬프트로, AI가 답변을 할 때 이 시스템 프롬프트를 바탕으로 답변을 생성한다.
- 시스템 프롬프트는 LLM 모델을 직접 수정하지 않고도 답변을 원하는 방식으로 조정할 수 있기에 비교적 쉽게 원하는 형태로의 답변의 일관성, 정확성, 신뢰성 등을 높일 수 있는 요소 중 하나이다.
- 또한 프롬프트에 원하는 바를 명확히 전달할수록 더 정확하고 신뢰할 수 있는 답변을 얻을 수 있다!
프롬프트 예시)👇
`oo 사이트에서 oo 파트에 대한 내용을 자세히 설명해줘`
시스템 프롬프트 예시)👇
`당신은 사용자가 제안한 상황에서 MBTI F(감정형)의 말을 T(사고형)에게 어떻게 말하면 좋을지 코칭해주는 코치입니다.`
`코칭 모드란?
사용자가 입력한 상황에서 F의 말을 T에게 어떻게 말하면 좋을지 코칭해주는 것입니다.
T가 **어떻게 상황을 이해하고 받아들였는지** 설명해주세요.
코칭 결과는 T에게 **실제로 전달할 수 있는 문장**으로 바꿔주세요.`
`응답 형식
"그렇게 얘기한다면 T는 이 말을 '...'로 이해할 거예요. 하지만 F가 전달하고자 하는 진짜 의도는 '...'이에요. 그러니 의도가 전달되도록 하기 위해서는 '...'라고 말하면 좋을 거예요." 형태로 답변하세요.`
2. 벡터화 & 임베딩
우리는 LLM에게 사람이 사용하는 언어(자연어)로 질문하고 데이터(이미지, 파일)등을 전달하지만, LLM은 사람이 이해하는 형태 그대로를 이해할 수 없다. 그래서 컴퓨터가 이해할 수 있도록 텍스트, 이미지와 같은 데이터들을 숫자로 변환하는 과정을 거친다. 이 과정이 벡터화이다.
벡터화된 데이터를 한 단계 더 가공해 각 단어들이 맥락과 의미를 포함하도록 하는 것을 임베딩이라고 한다.
그리고 이렇게 임베딩된 데이터를 고차원에 벡터로 표현해 이후에 사용자 입력에서 유사한 내용을 찾아낼 수 있도록 한다.
왜 중요할까?
F-T 번역기에 MBTI 관련 문서가 있다고 해보자. 각 문서에는 F,T에 대한 특성부터 F,T의 말투와 행동 패턴에 대한 내용이 있다.
만약 사용자가 'T인 남자친구가 이렇게 말했는데 왜 그런 말을 했을까?'라고 물었을 때,
문서의 많은 내용 중에 'T의 말투, 커뮤니케이션 특징'에 관한 내용이 사용자의 입력과 가장 관련이 있다는 걸 어떻게 찾을 수 있을까?
사람은 글(텍스트)를 읽고 의미에 따라 비슷한 것과 비슷하지 않은 것을 구분할 수 있지만, 컴퓨터에게는 '의미'라는 것부터 이해하기 어려운 것이다.
이를 컴퓨터가 할 수 있도록 텍스트를 비교 가능한 숫자(벡터)로 바꾸게 되는데 이를 임베딩이라고 한다.
LLM은 임베딩 과정을 통해 사용자가 제공하는 데이터와 질문을 이해하고 답변할 수 있다. 그리고 LLM이 답변 시 참고할 수 있는 여러 문서들(pdf, docs ...)은 임베딩 과정을 거쳐 벡터 스토어라는 곳에 저장한 뒤 사용자 입력을 보고 유사한 데이터를 뽑아서 더 정확한 답변을 제공하는데 사용된다.
예를 들어 '배'라는 단어로 생각해보자.
배는 '먹는 과일 배', '타는 배' 등 여러 의미를 가지고 있고 이는 단어가 사용되는 맥락에서 정해진다.
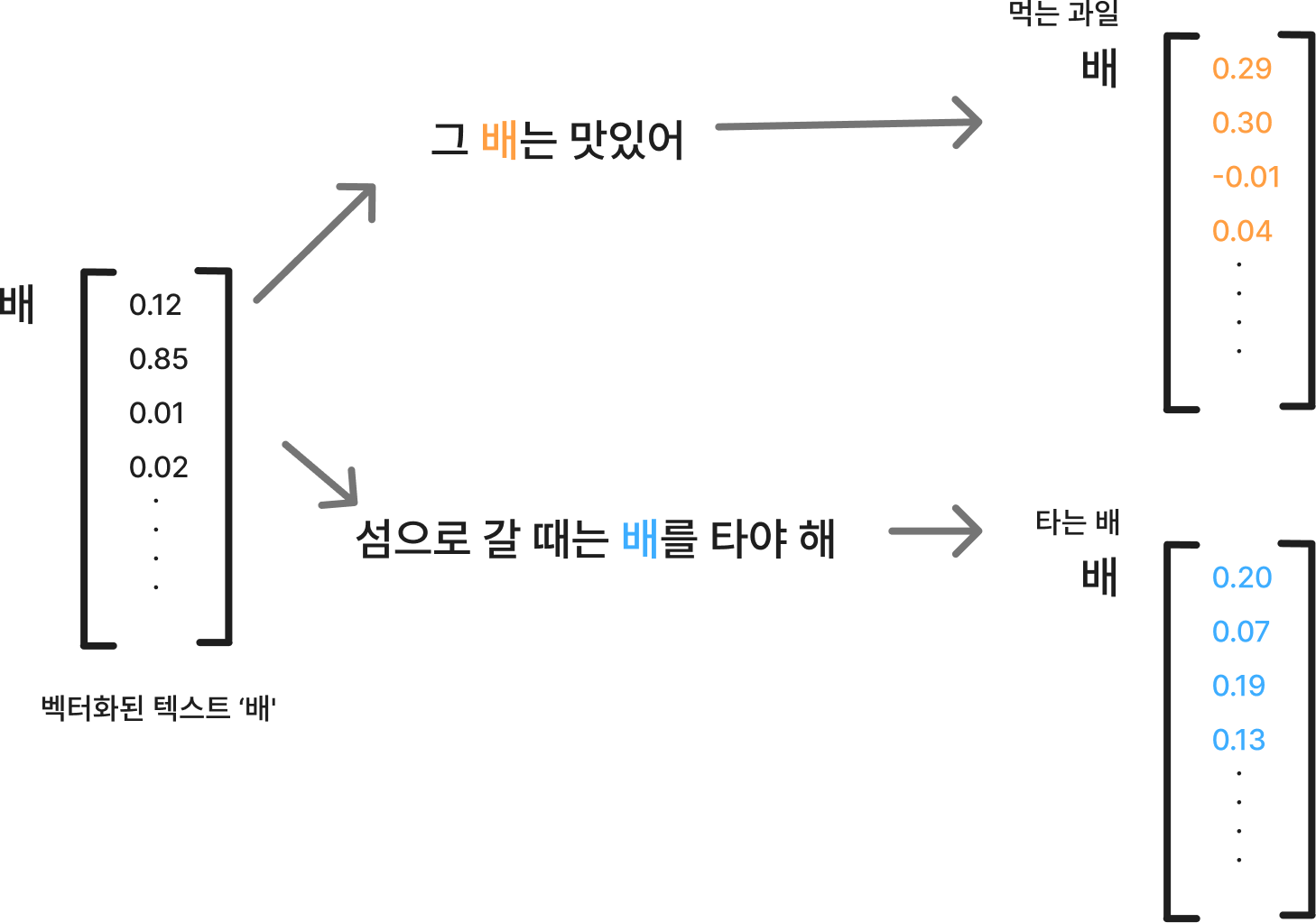
(실제 값이 아니라 벡터화와 임베딩의 차이를 보여주기 위한 임의의 값)
1. 벡터화 : 텍스트를 숫자로 변환
- '배' -> [0.12, 0.85, 0.01, 0.02,...]
2. 임베딩 : 단어에 의미를 포함해 벡터화
- '그 배는 맛있어' 문장에서 배는 '먹는 과일 배'라는 맥락을 가지게 되므로, '배'의 벡터는 [0.29, 0.30, -0.01, 0.04, ...] 로 바뀐다
- '섬으로 갈 때는 배를 타야 해' 문장에서 배는 '타는 배'라는 맥락을 가지게 되므로, '배'의 벡터는 [0.20, 0.07, 0.19, 0.13, ...] 로 바뀐다
즉, 맥락에 따라 동일한 단어인 '배'의 벡터가 다르게 변환되는 것이다.
3. 벡터 데이터베이스(벡터 스토어)
RAG에서는 외부 문서들을 저장하고 사용자의 입력이 주어졌을 때, 사용자의 입력과 유사한 내용을 외부 문서에서 찾아오는 역할이 필요하다. 이 과정에서 외부 문서들을 저장하고 사용자의 입력과 유사한 내용 검색을 담당하는 것이 벡터 데이터베이스이다.
F-T 번역기 프로젝트에서는 MBTI F/T에 대한 정보와 밈에 관한 정보를 벡터 DB에 저장하고
사용자 입력이 주어졌을 때, 벡터 DB에서 유사한 정보를 가져와 F/T의 의도를 알려주고 밈에 대한 정보를 참고해 번역을 진행하도록 할 것이다.
벡터 DB의 역할을 기술적으로 풀어보면 임베딩 과정을 통해 생성된 벡터들을 저장하고 관리/검색할 수 있게 도와주는 데이터베이스이다.
RDB나 NoSQL처럼 데이터를 저장하고 관리하는 데이터베이스이지만, 저장되는 데이터가 벡터에 특화된 데이터베이스이다.
벡터 검색은 사용자의 입력과 유사한 데이터를 빠르게 찾아내는 검색 기법으로 벡터 유사도 검색, 근사 최인접 이웃(ANN) 알고리즘 등이 있다. 벡터 간의 거리나 각도를 측정해 벡터가 서로 가까울수록 의미적으로 더 유사한 데이터라고 판단한다.
ChromaDB vs Google File Search API - 무엇을 선택할까?
벡터 DB는 Chroma, FAISS, Pinecone 등 다양한 라이브러리가 있지만, F-T 번역기 프로젝트에서는 Chroma를 사용할 것이다.
Chroma와 구글의 Gemini API의 파일 검색 API 중 어떤 것이 더 좋을까 고민이 되었다.
| 항목 | ChromaDB (직접 구축) | Google File Search API |
| 임베딩 생성 | 직접 호출 | 자동 |
| 청킹 | 직접 구현 필요 | 자동 (커스텀 청킹 설정 가능) |
| 벡터 저장 | ChromaDB(로컬 or 서버) | Google 관리형 FileSearchStore |
| 인덱싱 | ChromaDB가 자동 처리 | Google이 자동 처리 |
| 유사도 검색 | `similaritySearch()` 직접 호출 | generateContent에 tools로 전달하면 자동 |
| 메타데이터 필터링 | 지원($and, $eq 등) | 지원 (metadata_filter) |
| 인프라 관리 | Docker로 ChromaDB 서버 운영 필요 | 완전 관리형 (서버리스) |
| 인용/출저 | 직접 구현 | grounding_metadata로 자동 제공 |
비용
Google File Search API
- 색인 생성 시: 임베딩 비용 = 토큰 1백만 개당 $0.15 (1회성)
- 저장: 무료
- 쿼리 시 임베딩: 무료
- 검색된 문서 토큰: 일반 입력 토큰 요금으로 과금
ChromaDB 직접 구축 (현재 방식)
- 색인 생성 시: 동일하게 gemini-embedding-001 API 호출 → 토큰 1백만 개당 $0.15
- 저장: ChromaDB 서버 운영 비용 (로컬이면 무료, 클라우드 배포 시 서버 비용 발생)
- 쿼리 시 임베딩: 매 쿼리마다 임베딩 API 호출 → 토큰 1백만 개당 $0.15
- 검색된 문서 토큰: 동일하게 입력 토큰으로 과금
비용에 많은 영향을 미칠 부분은 특히 쿼리 임베딩일 것 같다.
- File Search: 쿼리 임베딩이 무료,
- ChromaDB: 쿼리할 때마다 embedQuery()를 호출하므로 매번 임베딩 비용 발생
쿼리가 많아 진다면, Google File Search API가 더 저렴할 것이다.
현재 프로젝트는 소규모 데이터를 기반으로 LangChain을 활용한 RAG를 학습하는 것에 초점을 두고 있기 때문에
청킹, 임베딩 모델, 검색 등에 관해 자유롭게 커스텀해볼 수 있는 ChromaDB를 선택했다.
만약, 이 프로젝트를 배포한다면 쿼리 임베딩 비용이 무료이고 자동 관리를 해줄 수 있는 Google File Search API를 선택할 것이다.
RAG 작동방식
RAG를 구성하는 핵심 요소들에 대해 알아봤으니 이를 바탕으로 RAG가 어떻게 동작하는지 알아보자.
각 단계를 실제로 F-T 번역기를 사용할 때의 흐름을 예로 들어 차근차근 알아보자.
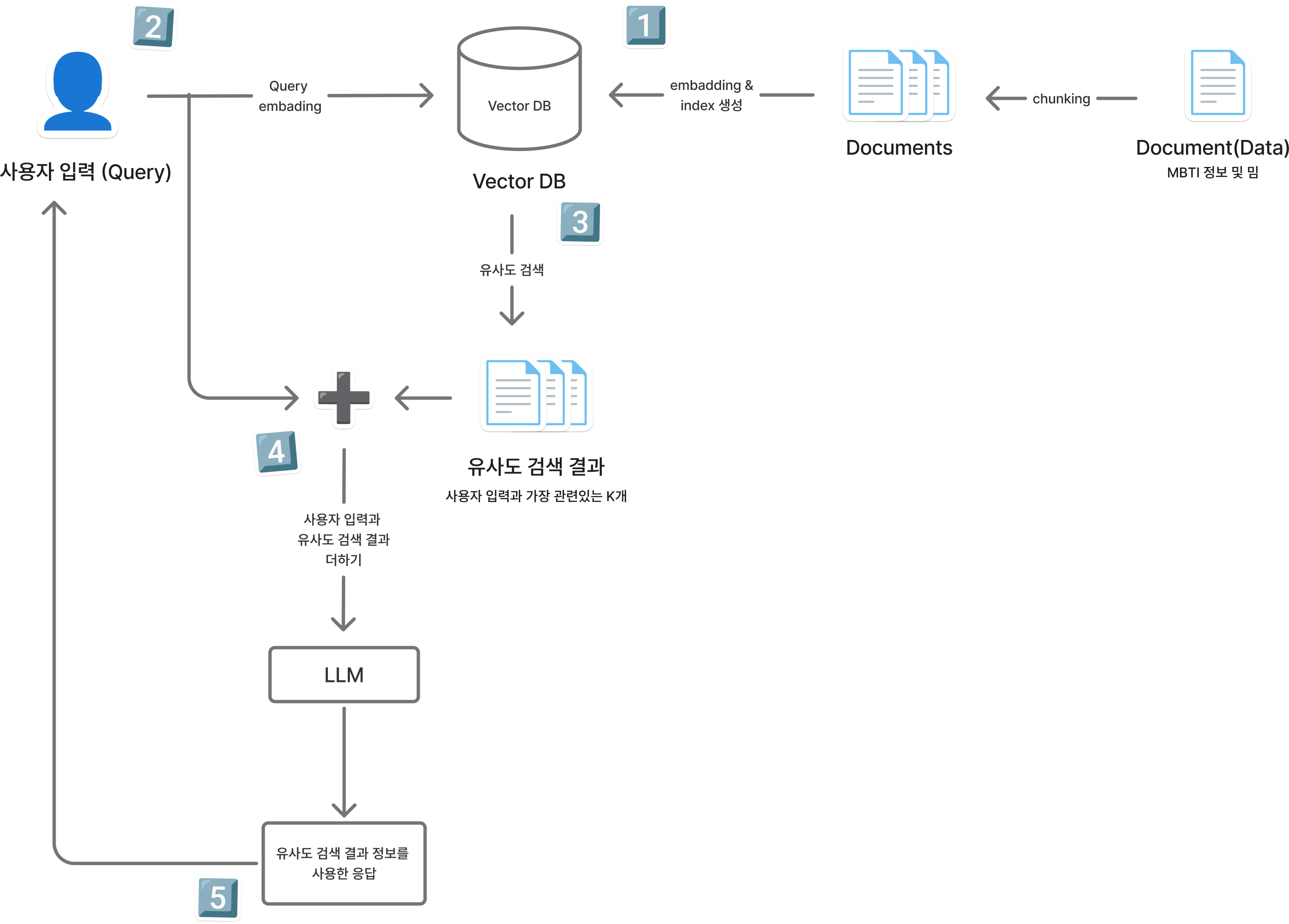
1. MBTI F/T에 대한 정보와 밈에 관한 정보를 벡터 DB에 저장한다.
2. 사용자가 질문을 하면 질문을 임베딩 모델에 입력하여 임베딩 벡터를 생성한다.
3. 임베딩된 사용자 질문 벡터를 기반으로 벡터 DB에서 가장 유사한 데이터를 찾는다.
4. 벡터 DB에서 찾은 데이터와 사용자 질문을 LLM에 입력하여 답변을 생성한다.
5. 답변을 생성 후 사용자에게 출력한다.
참고
https://ai.google.dev/gemini-api/docs/file-search?authuser=1&hl=ko#citations
파일 검색 | Gemini API | Google AI for Developers
Gemini API의 파일 검색 도구로 RAG 솔루션 빌드 시작하기
ai.google.dev
https://brunch.co.kr/@harryban0917/334
08화 LLM의 조력자-임베딩 모델이란 무엇일까?
검색증강생성(RAG) 속 임베딩의 역할은? | GPT-4o나 Gemini와 같은 초거대언어모델(LLM)은 얼핏 우리 인간이 그러하듯 문장과 단어를 이해하고 있는 것처럼 보이지만 사실은 여느 컴퓨터 프로그램이
brunch.co.kr
https://youtu.be/g38aoGttLhI?si=Aaw-75YePtAz6fzs
'AI' 카테고리의 다른 글
| [Cursor AI로 PR 코드 리뷰 자동화하기] Skill 만들기부터 통계 측정까지 (0) | 2026.04.01 |
|---|---|
| [프로젝트 - F-T 번역기 ] 프롤로그 (1) | 2026.03.11 |


댓글